今天要介紹RAG的工作流程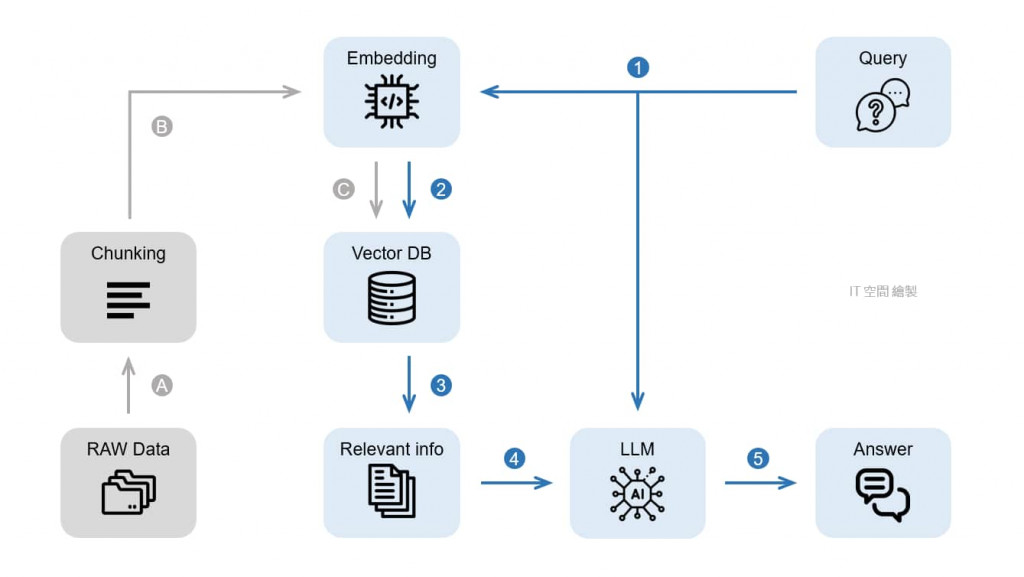
索引 (Indexing) 階段
將資料切塊 (A)
Loader 負責從原始資料來源(例如文件、網頁、專業文獻等)中讀取數據,並將其切分成較小的區塊。這樣做的目的是讓資料更容易進行後續的檢索和處理,因為處理過大或太多文字會影響系統效率。
轉換成向量 (B)
在這一步會協助準備資料,讓其可以被轉換成向量格式。
Embedding 模型:資料會被轉換成向量(數字表示的形式),這樣能利用向量之間的距離來判斷資料的相似程度。這一步是為了讓後續的檢索更精確。
儲存向量資料 (C)
轉換好的向量資料(以及原始內容)會被儲存進向量資料庫中,以供後續的檢索使用。當資料有更新或新增時,Loader 會負責重新載入和索引這些資料。
檢索(Retrieval)階段
查詢轉換成向量 (1)
當使用者輸入問題時,Retriever 會將這個查詢轉換成向量,使其能夠與資料庫中的向量進行比對。
檢索相關資料 (2, 3)
Retriever 利用查詢的向量,從向量資料庫中搜尋出最相關的資料區塊。這些篩選出的區塊就是用來輔助生成回應的關鍵資料。
生成(Generation) 階段
生成答案 (4, 5)
LLM Generator(大型語言模型)會將 Retriever 提供的「相關資料區塊」和使用者的問題結合,生成最終的回應。這樣做能提升回答的精準度,因為有外部資料可參考,避免回應過於籠統。


 iThome鐵人賽
iThome鐵人賽